Pergunta
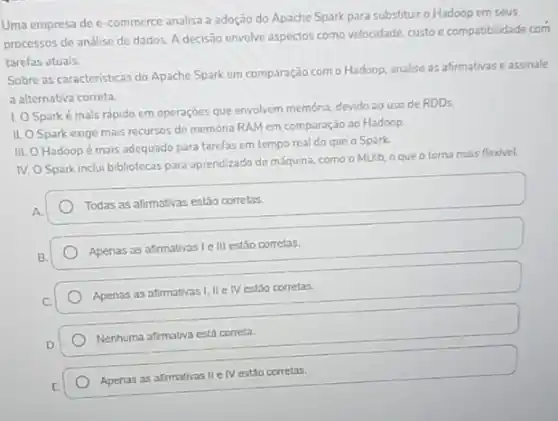
Uma empresa de e -commerce analisa a adoção do Apache Spark para substituir o Hadoop em seus processos de análise de dados. A decisão envolve aspectos como velocidade, custo e compatibilidade com tarefas atuals. Sobre as caracteristicas do Apache Spark em comparação como Hadoop, analise as afirmativas e assinale a alternativa correta. 1. O Sparké mals rápido em operações que envolvem memoria, devido ao uso de RDDs ILO Spark exige mais recursos de memóna RAM em comparação 30 Hadoop. III. O Hadoopé mais adequado para tarefas em tempo real do que o Spark IV. O Spark inclui bibliotecas para aprendizado de máquina, como o MLlib o que o torna mais flexivel. A. Todas as afirmativas estão corretas. Apenas as afirmativas le III estão corretas. Apenas as afimativas I IIe IV estǎo corretas D. Nenhuma afrmativa está correta. E. Apenas as afirmativas IIe IV estao corretas.
Solução
 Verification of experts
Verification of experts4.1211 Voting

SérgioVeterano · Tutor por 10 anos
Responder
alternativa correta é a letra C: Apenas as afirmativas I, II e IV estão corretas.
Vamos analisar cada afirmativa:
I. O Spark é mais rápido em operações que envolvem memória, devido ao uso de RDDs (Resilient Distributed Datasets). Isso é verdadeiro, pois o Spark é projetado para ser mais eficiente em operações que utilizam a memória, em comparação com o Hadoop.
II. O Spark exige mais recursos de memória RAM em comparação com o Hadoop. Isso também é verdadeiro, pois o Spark utiliza a memória RAM para armazenar dados e realizar operações mais rapidamente, o que pode exigir mais recursos de memória em comparação com o Hadoop.
III. O Hadoop é mais adequado para tarefas em tempo real do que o Spark. Isso é falso, pois o Spark é mais adequado para tarefas em tempo real devido à sua capacidade de processar dados em streaming e realizar operações em tempo real.
IV. O Spark inclui bibliotecas para aprendizado de máquina, como o MLlib, o que o torna mais flexível. Isso é verdadeiro, pois o Spark possui bibliotecas para aprendizado de máquina, como o MLlib, que permitem realizar tarefas de aprendizado de máquina de forma eficiente.
Portanto, a alternativa correta é a letra C: Apenas as afirmativas I, II e IV estão corretas.
Vamos analisar cada afirmativa:
I. O Spark é mais rápido em operações que envolvem memória, devido ao uso de RDDs (Resilient Distributed Datasets). Isso é verdadeiro, pois o Spark é projetado para ser mais eficiente em operações que utilizam a memória, em comparação com o Hadoop.
II. O Spark exige mais recursos de memória RAM em comparação com o Hadoop. Isso também é verdadeiro, pois o Spark utiliza a memória RAM para armazenar dados e realizar operações mais rapidamente, o que pode exigir mais recursos de memória em comparação com o Hadoop.
III. O Hadoop é mais adequado para tarefas em tempo real do que o Spark. Isso é falso, pois o Spark é mais adequado para tarefas em tempo real devido à sua capacidade de processar dados em streaming e realizar operações em tempo real.
IV. O Spark inclui bibliotecas para aprendizado de máquina, como o MLlib, o que o torna mais flexível. Isso é verdadeiro, pois o Spark possui bibliotecas para aprendizado de máquina, como o MLlib, que permitem realizar tarefas de aprendizado de máquina de forma eficiente.
Portanto, a alternativa correta é a letra C: Apenas as afirmativas I, II e IV estão corretas.
Clique para avaliar: